Introduction to Feature Engineering
Feature engineering is often considered the heart of machine learning. It's the process that can make or break your model's performance. By intelligently crafting features from raw data, you can capture complex patterns and relationships that a model might otherwise miss. This article provides a comprehensive introduction to feature engineering, explaining its significance, exploring different types of features, and offering practical examples—including visualizations and code snippets—to help you master this essential skill.
1. What is Feature Engineering?
1.1 Definition
Feature engineering is the process of using domain knowledge to extract features (characteristics, properties, attributes) from raw data to improve the performance of machine learning algorithms. It involves creating new features, transforming existing ones, and selecting the most relevant features for modeling.
1.2 Why is Feature Engineering Important?
The adage "Garbage in, garbage out" holds especially true in machine learning. The quality and relevance of your features directly influence your model's ability to learn and generalize. Effective feature engineering can:
- Simplify the complexity of the data.
- Highlight underlying patterns and relationships.
- Reduce overfitting by eliminating noise.
- Enhance model interpretability.
1.3 The Role of Domain Knowledge
While statistical techniques are essential, domain knowledge is invaluable in feature engineering. Understanding the nuances of the data and the problem domain allows you to create features that capture meaningful relationships. For instance, in healthcare data, combining symptoms to predict a disease requires medical expertise.
2. Types of Features
Understanding the types of features in your dataset is crucial for selecting appropriate preprocessing and modeling techniques.
2.1 Numerical Features
Numerical features represent quantifiable measurements and can be:
- Continuous: Can take any value within a range (e.g., temperature).
- Discrete: Can only take specific values, often counts (e.g., number of children).
Examples:
- Age: Continuous numerical feature.
- Salary: Often treated as continuous.
- Number of Purchases: Discrete numerical feature.
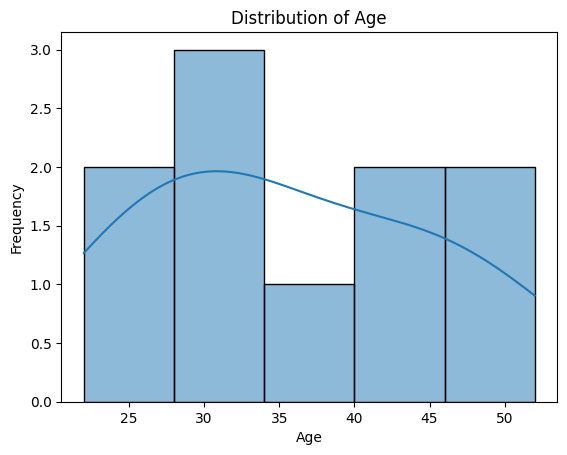
Figure 1: Distribution of Numerical Features with KDE Example.
2.2 Categorical Features
Categorical features represent qualitative data divided into categories. These are often non-numeric and require encoding.
Examples:
- Gender: Male, Female.
- Color: Red, Blue, Green.
- Product Type: Electronics, Furniture, Clothing.
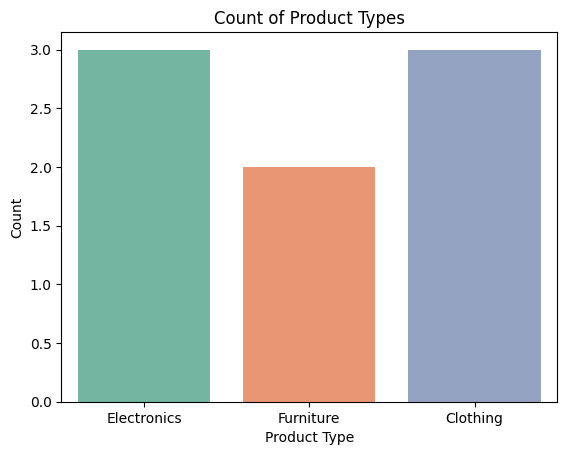
Figure 2: Categorical Features Example.
2.3 Ordinal Features
Ordinal features are categorical features with a meaningful order but no consistent difference between categories.
Examples:
- Education Level: High School < Bachelor's = Master's > PhD.
- Customer Satisfaction: Poor < Fair < Good < Excellent.
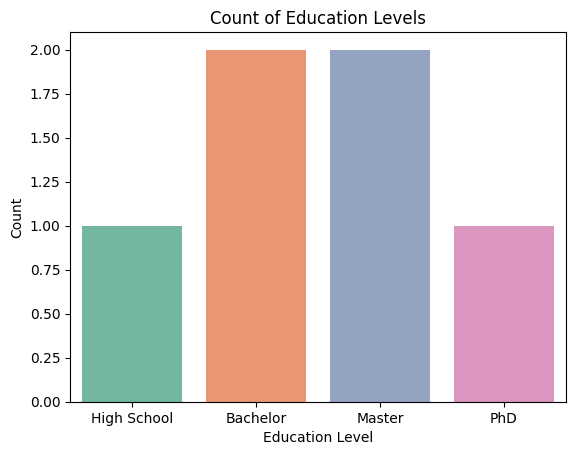
Figure 3: Ordinal Features Example.
2.4 Temporal Features
Temporal features represent data that is related to time, making them crucial for understanding trends, patterns, and cycles in datasets. These features can be challenging to analyze due to their cyclical nature (e.g., hours in a day, seasons in a year) and the potential for time-based correlations.
Examples of Temporal Features:
- Date of Purchase: The specific date when a transaction occurs.
- Time on Site: The duration a user spends on a website, often measured in seconds or minutes.
- Year of Birth: The year an individual was born, which can be used to derive age-related insights.
Figure 4: Temporal Features Example.
2.5 Textual Features
Textual features consist of unstructured text data, requiring techniques like Natural Language Processing (NLP) for feature extraction.
Examples:
- Customer Reviews
- Product Descriptions
- Social Media Posts

Figure 5: Word Cloud Example.
3. The Process of Feature Engineering
3.1 Feature Creation
Feature creation involves generating new features that may not be present in the raw data but can be derived from it.
Techniques:
- Interaction Feature: Multiplying two features together to capture their combined effect.
- Polynomial Feature: Squaring or cubing a feature to capture non-linear relationships.
3.2 Feature Transformation
Feature transformation modifies existing features to better suit the model’s needs. This can involve scaling, normalizing, or applying mathematical transformations like logarithms to deal with skewed data distributions.
Examples:
- Log Transformation: Applying a logarithm to a skewed feature to reduce skewness.
- Scaling: Standardizing features to have zero mean and unit variance.
3.3 Feature Selection
Feature selection is the process of identifying the most important features from a dataset, reducing the dimensionality and potentially improving model performance. This can be done through statistical methods or model-based techniques.
Examples:
- Removing features with low variance.
- Selecting features based on their correlation with the target variable.
4. Challenges in Feature Engineering
4.1 Data Leakage
Data leakage occurs when information from outside the training dataset is used to create the model, causing it to perform unrealistically well during training.
Example:
Including a feature that is only available in hindsight, such as a future event's outcome, can lead to data leakage.
Prevention:
- Split data into training and testing sets before feature engineering.
- Avoid using target-related features in feature creation.
4.2 Overfitting
Overfitting happens when the model learns noise instead of the underlying pattern, often due to too many features.
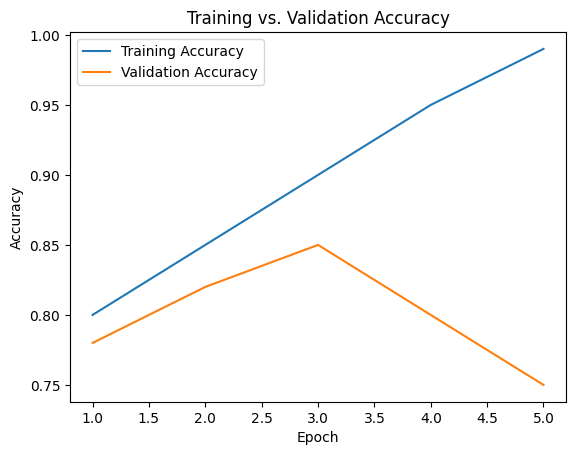
Figure 6: Plot training vs. validation accuracy to detect overfitting.
4.3 Curse of Dimensionality
High-dimensional data can make models more complex and computationally intensive, often leading to poorer performance.
Prevention:
- Use dimensionality reduction techniques like PCA.
- Select only the most relevant features.
5. Best Practices in Feature Engineering
5.1 Start Simple
Begin with straightforward features and transformations before moving to complex ones.
5.2 Iterate and Experiment
Feature engineering is an iterative process. Continuously test and validate new features.
5.3 Use Domain Knowledge
Leverage expertise from the field to create meaningful features.
5.4 Monitor for Overfitting
Regularly validate your model on unseen data to ensure it generalizes well.
5.5 Document Your Process
Keep detailed notes on the features created, transformations applied, and reasons behind each decision.
6. Conclusion
6.1 Summary of Key Concepts
Feature engineering is a critical step that involves creating, transforming, and selecting features to improve model performance. By understanding different types of features and employing various techniques, you can enhance your model's ability to learn from data.
6.2 Next Steps
As you proceed, you’ll learn when and how to apply specific feature engineering techniques in different contexts. The next article will guide you through the decision-making process for choosing the right features based on the characteristics of your data and the requirements of your model.