Descriptive Statistics
Descriptive statistics are fundamental for summarizing and understanding the essential characteristics of a dataset. By employing various statistical measures, we can describe the central tendency, dispersion, and overall shape of the data distribution. This article delves into these concepts in detail, providing the necessary tools to interpret and analyze data effectively.
Measures of Central Tendency
Central tendency measures provide insight into where the center of a dataset lies. They include the mean, median, and mode, each of which offers a different perspective on the data.
1. Mean
The mean is the arithmetic average of a dataset and is calculated by summing all the data points and dividing by the number of points. It is a widely used measure of central tendency, but it can be sensitive to outliers.
Example: Consider the dataset . The mean is calculated as follows:
- The sum of the data points is .
- The number of data points, , is 9.
The mean is:
The mean provides a general idea of the data's central value, but if the dataset included a very large or small outlier, the mean could be misleading.
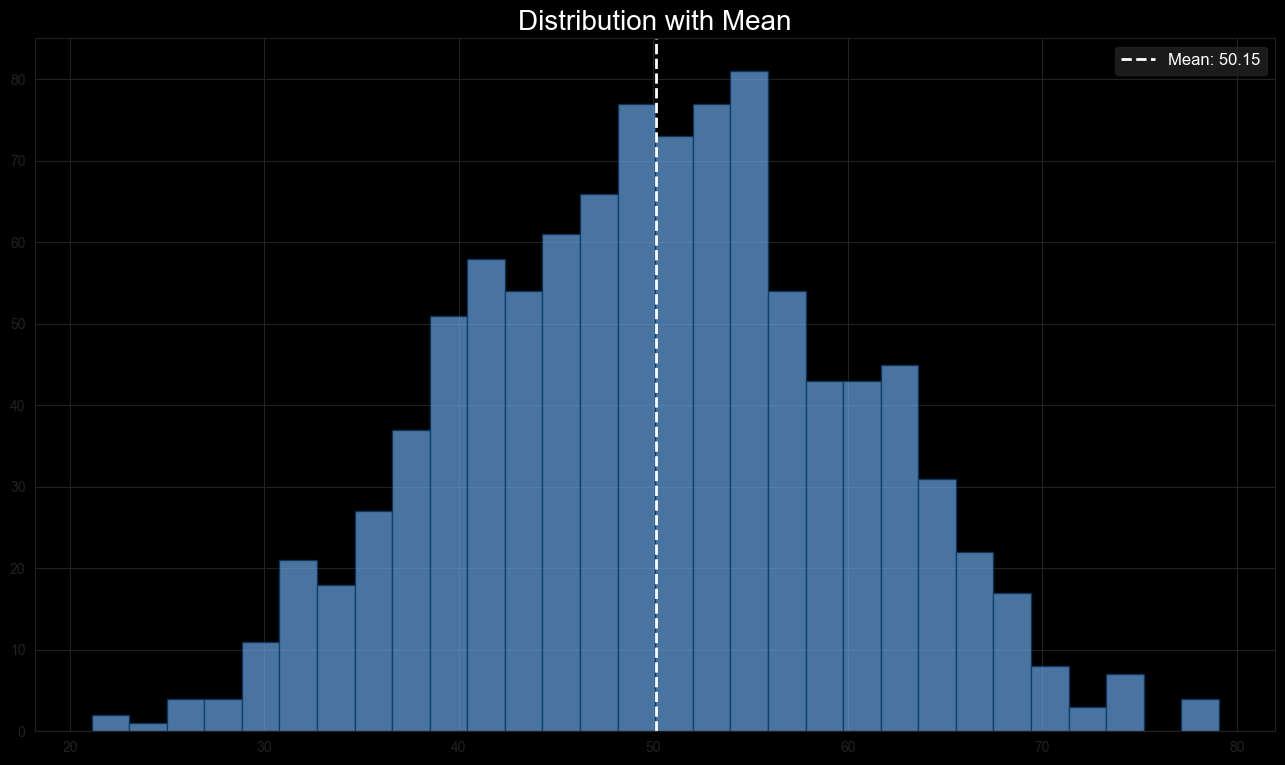
Figure 1: Mean Distribution showing a normal distribution curve with a mean marked by a vertical dashed line.
2. Median
The median is the middle value of a dataset when it is ordered from smallest to largest. It is a robust measure of central tendency, particularly in skewed distributions, because it is not affected by outliers.
For a dataset , sorted in ascending order:
- If is odd, the median is .
- If is even, the median is the average of the two middle values: .
Example
Example: Suppose we have a dataset generated from a normal distribution centered around 50. The median of this dataset would be approximately , as shown in the histogram below.
The dataset is modeled after a typical normal distribution, and the median represents the middle value when the data points are ordered. The median value is marked by a vertical dashed line in the histogram.
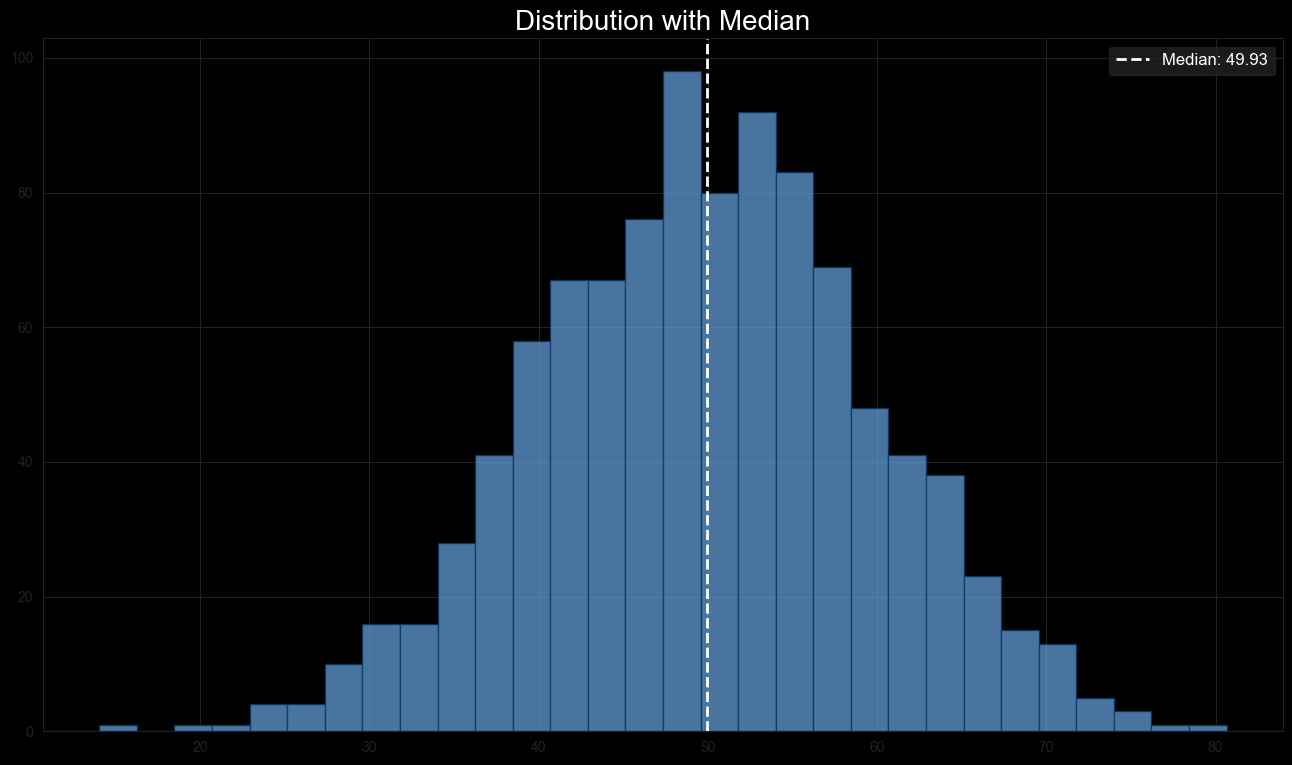
Figure 2: Median Distribution showing a normal distribution curve with the median marked by a vertical dashed line.
3. Mode
The mode is the value that appears most frequently in a dataset. A dataset can be:
- Unimodal: Having one mode.
- Bimodal: Having two modes.
- Multimodal: Having more than two modes.
- No mode: If no value repeats.
In the context of a bimodal distribution, the dataset has two distinct peaks, each representing a mode.
Example: Consider a dataset that is bimodal, meaning it has two modes. If the dataset is (X = {50, 53, 57, 60, 63, 65}), the modes represent the most frequently occurring values in the dataset. In this example, the dataset shows two distinct peaks at approximately 50 and 60.
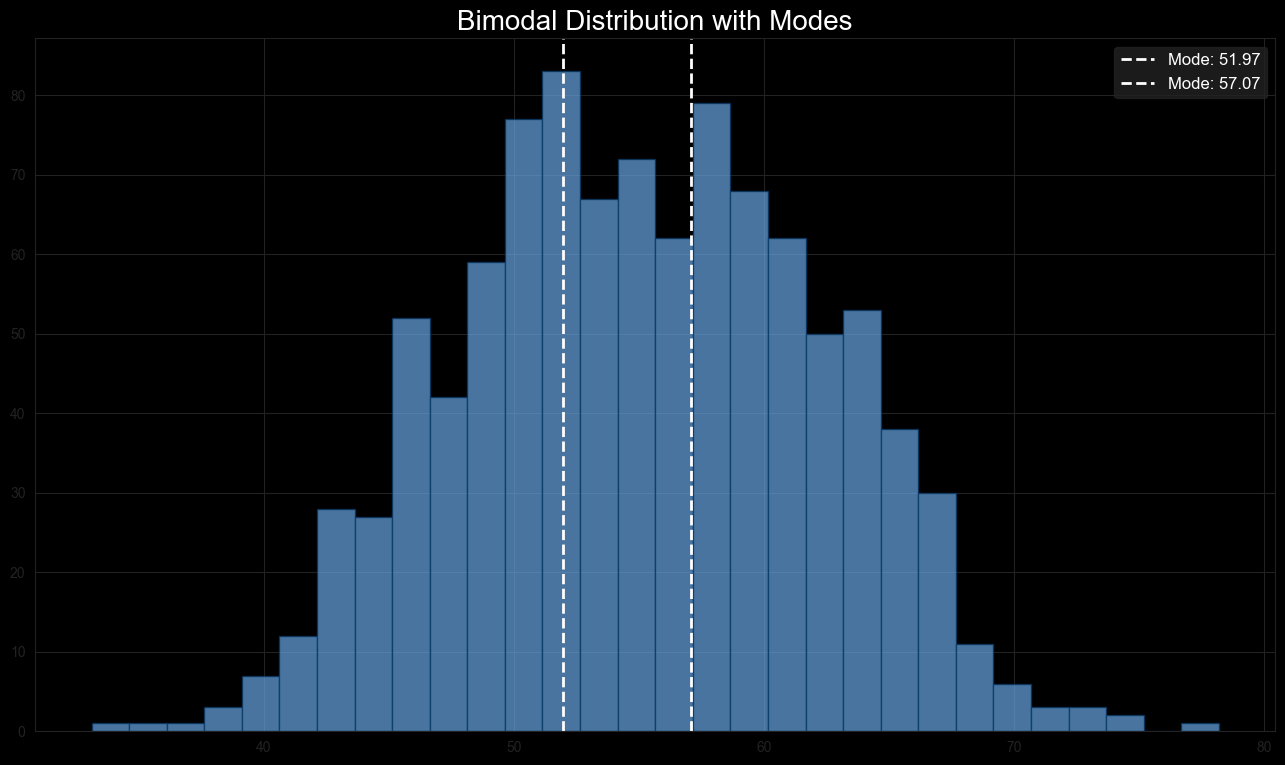
Figure 3: Mode Distribution showing a bimodal distribution, with the modes at approximately 50 and 60, marked by vertical dashed lines.
Measures of Dispersion
While measures of central tendency provide insights into the data’s center, measures of dispersion describe the spread of the data. These include range, variance, and standard deviation.
1. Range
The range is the simplest measure of dispersion and is calculated as the difference between the maximum and minimum values in a dataset.
Example: For the dataset , the range is:
The range provides a quick sense of the spread of the data but is highly sensitive to outliers.
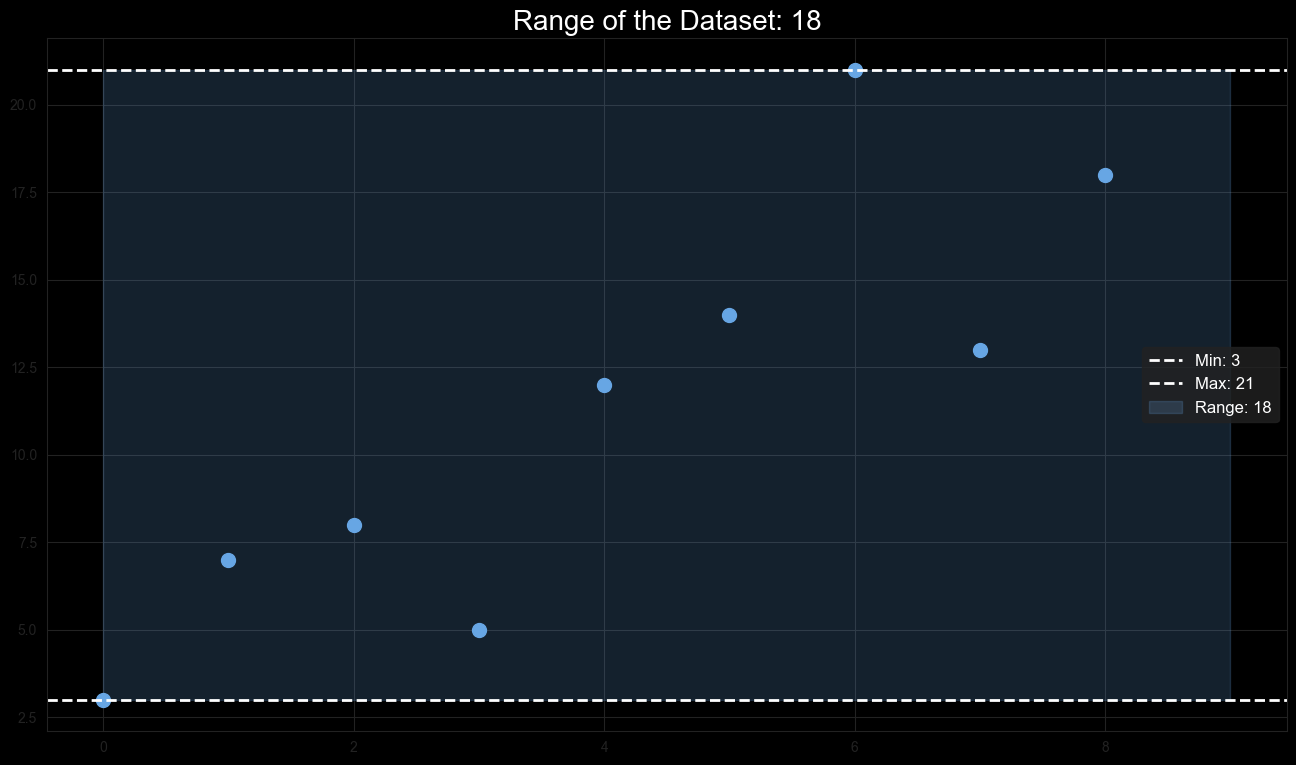
Figure 4: Range Visualization showing the minimum and maximum values, with a shaded area representing the range.
2. Variance
Variance measures how far each data point is from the mean and thus provides a measure of the data's overall spread. It is particularly useful for datasets where the values deviate significantly from the mean.
For a population:
For a sample:
Where:
- is the population mean.
- is the sample mean.
- is the number of data points.
Example: Consider the sample dataset .
- The mean is .
- The squared deviations from the mean are , , , , and .
The sample variance is:
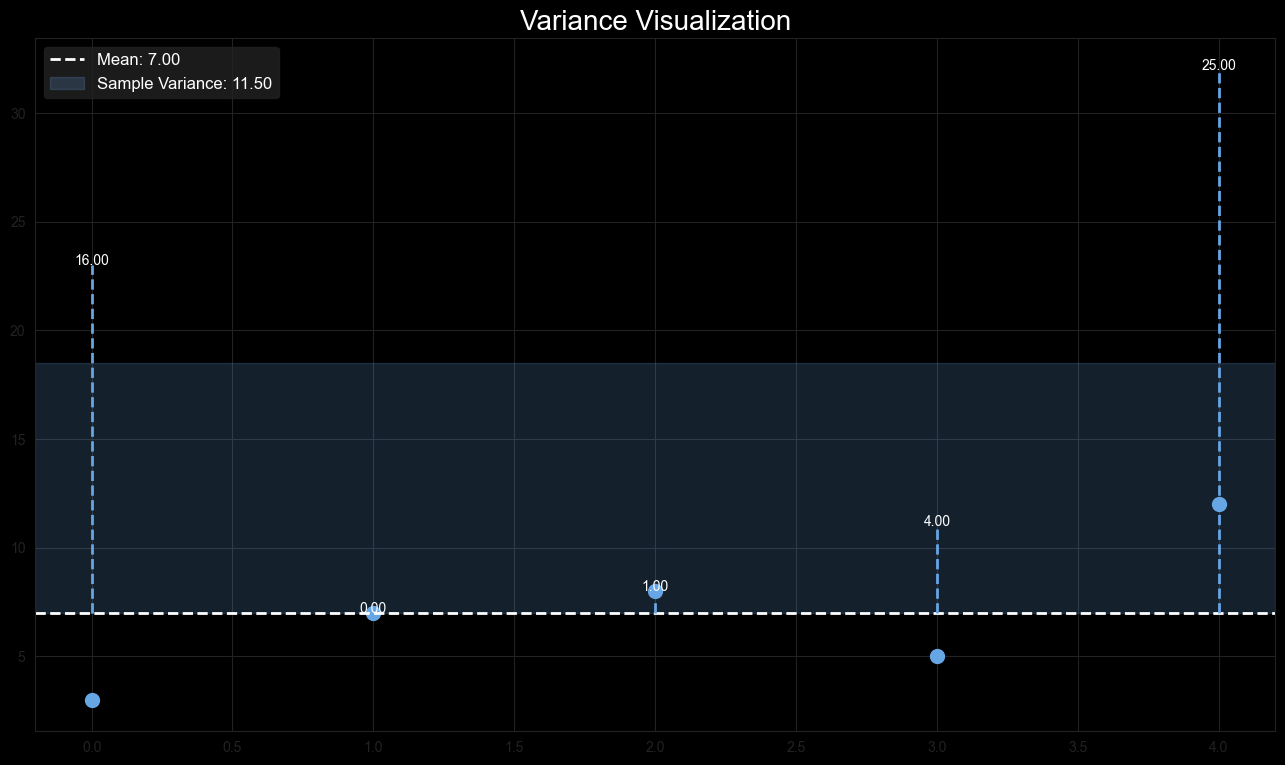
Figure 5: Variance Visualization showing the squared deviations from the mean.
3. Standard Deviation
The standard deviation is the square root of the variance, providing a measure of the average distance from the mean. It is in the same units as the data, making it more interpretable than variance.
For a population:
For a sample:
Example: Using the sample variance calculated above (), the standard deviation is:
Standard deviation provides an understanding of how spread out the data points are from the mean. A higher standard deviation indicates greater variability.
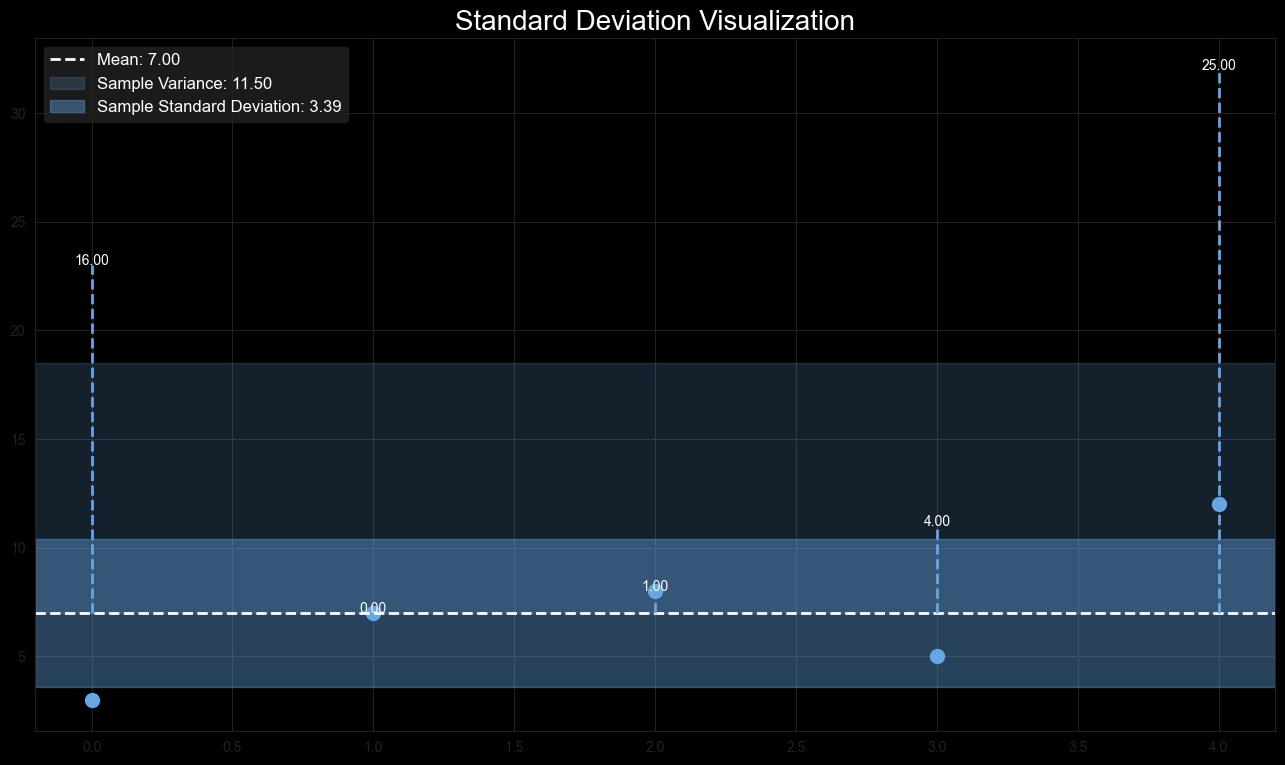
Figure 6: Standard Deviation Visualization showing the standard deviation as a shaded area around the mean.
Importance of Descriptive Statistics
Descriptive statistics are crucial for summarizing large datasets and identifying patterns. They provide the foundation for further statistical analysis and decision-making processes. By understanding the central tendency, dispersion, skewness, and kurtosis, you can gain valuable insights into the data before applying more complex analytical techniques.
Applications in Data Science
- Data Exploration: Descriptive statistics are the first step in exploring and understanding the dataset.
- Data Cleaning: Identifying outliers and unusual patterns helps in cleaning the data.
- Feature Engineering: Insights gained from descriptive statistics can guide the creation of new features in a dataset.
Conclusion
Descriptive statistics are indispensable tools in data analysis, providing a summary of the data's key characteristics. By mastering these concepts, you’ll be better equipped to analyze, interpret, and communicate your findings, laying the groundwork for more advanced statistical techniques.